
SPSS Uygulama – Lojistik Regresyon Analizi
Lojistik regresyon analizi için SPSS programında şu adımlar izlenir: Analyze menüsünden Regresyon seçeneği seçilir ve ardından Binary Logistic seçeneği işaretlenir. Bu işlem, lojistik regresyonu analiz etmek için diyalog kutusunu açar. Diyalog kutusunun üst kısmındaki Dependent yazan alana bağımlı değişken aktarılır. Bağımsız değişkenler ise Covariates kısmına sol taraftan aktarılır. Daha sonra, hesaplama yöntemi seçimi yapılır. Bu seçenekler arasında Enter yöntemi, tüm bağımsız değişkenlerin aynı anda analize dahil edildiği yöntemdir, diğer yöntemler de seçilebilir.
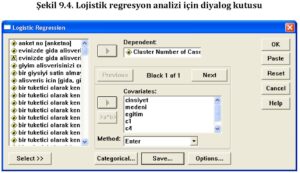
Kaynak: Altunişik, R., Coşkun, R., Bayraktaroğlu, S., & Yildirim, E. (2007). Sosyal bilimlerde araştırma yöntemleri. Sakarya Yayıncılık, Sakarya, 226, 103-118.
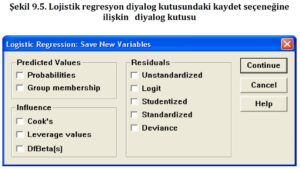
Kaynak: Altunişik, R., Coşkun, R., Bayraktaroğlu, S., & Yildirim, E. (2007). Sosyal bilimlerde araştırma yöntemleri. Sakarya Yayıncılık, Sakarya, 226, 103-118.
Şekil 9.5’teki (Figure 9.5) Save seçeneği altında, tahmin edilen değerlere ilişkin seçenekler sol üst kısımda yer almaktadır. Bu seçenekler, lojistik regresyon analizi sonucunda elde edilen tahmin edilen değerlerin nasıl kaydedileceğini belirlemektedir. Sağ tarafta ise hata paylarına ilişkin bilgiler bulunmaktadır. Bu bilgiler, lojistik regresyon analizinde elde edilen hata paylarının nasıl kaydedileceğini ve kullanılabilecek istatistiklere ilişkin seçenekleri içermektedir.
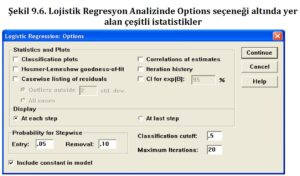
Kaynak: Altunişik, R., Coşkun, R., Bayraktaroğlu, S., & Yildirim, E. (2007). Sosyal bilimlerde araştırma yöntemleri. Sakarya Yayıncılık, Sakarya, 226, 103-118.
Bu bölümde, model performansını değerlendirmek için çeşitli istatistik analiz seçenekleri bulunmaktadır. Bu seçenekler, lojistik regresyon modelinin ne kadar iyi uyum sağladığını değerlendirmek için kullanılabilir. Ancak, daha kapsamlı bir anlayış için ileri seviye istatistik ve çok değişkenli veri analizi kitaplarından daha fazla bilgi edinmek önerilir. Bu kaynaklar, regresyon analizi ve lojistik regresyon analizi hakkında daha derinlemesine bilgi sunabilir ve model performansının nasıl değerlendirileceği konusunda daha fazla ayrıntı sağlayabilir.
Analiz
Analiz
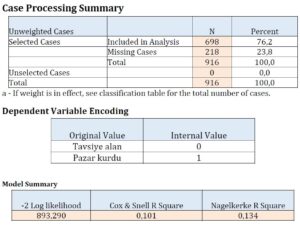
Kaynak: Altunişik, R., Coşkun, R., Bayraktaroğlu, S., & Yildirim, E. (2007). Sosyal bilimlerde araştırma yöntemleri. Sakarya Yayıncılık, Sakarya, 226, 103-118.
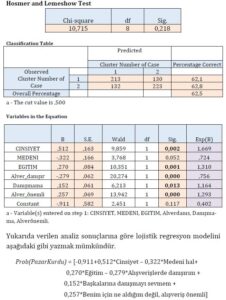
Analiz çıktılarına göre, araştırmada toplam 916 katılımcı bulunduğu ancak sadece 698 katılımcının tavsiye alan veya pazar kurdu grubuna ait olduğu belirlenmiştir. Bu nedenle analiz, yalnızca 698 kişi üzerinde gerçekleştirilmiştir ve 218 kişi analiz dışı tutulmuştur (missing cases). İkinci tabloda, bağımlı değişkenin kodlama bilgileri yer almaktadır. Bu tabloda, tavsiye alan ve pazar kurdu gruplarına ilişkin kodlamalar (0 ve 1) görülmektedir. Üçüncü tabloda ise modelle ilgili çeşitli test istatistikleri sunulmaktadır. Bu istatistikler arasında “-2LL”, “Cox & Snell R Kare” ve “Nagelkerke R Kare” yer almaktadır. “-2LL” değeri ne kadar küçükse, modelin uyumunun o kadar iyi olduğunu gösterir. İlave bir değişkenin modele dahil edilmesiyle “-2LL” değerindeki düşüş, o değişkenin modeldeki iyileşmeye katkısını gösterir.
Diğer iki gösterge olan “pseudo R2” ve “Goodness of Fit” istatistikleri de modelin açıklama gücünü gösteren ölçütlerdir. “pseudo R2” istatistiği, -2LL değerindeki iyileşmeye dayanarak hesaplanır ve yukarıda belirtilen R2logit formülüyle hesaplanır. “Goodness of Fit” (Uygunluk İndeksi), tahmin edilen olasılıkların gerçekleşen olasılıklarla karşılaştırılmasına dayanan bir ölçüttür. Bu değerin artması, modelin geliştiğini gösterir. Bunları takip eden Hosmer ve Lemeshow göstergesi, bağımlı değişkenin tahmin edilen ve gerçekleşen değerleri arasındaki ilişkiyi ölçer. Gözlemlenen ve tahmin edilen değerler arasındaki farkın küçük olması, daha iyi bir model uyumunu gösterir. İstatistiksel olarak anlamsız bir ki-kare değeri, sınıflandırma farkının modelin iyi bir uyum sağladığı anlamına geldiği şeklinde yorumlanır. Tüm bu göstergeleri değerlendirdiğimizde, modelin uygun olduğu sonucuna varılabilir.
Sınıflandırma tablosu, modelin etkinliği hakkında bir diğer gösterge olarak kullanılabilir. Bu tabloya göre, önerilen modelin genel olarak %62,5 doğru sınıflandırma oranı elde ettiği gözlemlenmektedir. Bu da modelin belirli bir doğruluk seviyesiyle sınıflandırma yapabildiğini gösterir.
“Variables in the Equation” tablosunda, modelde yer alan bağımsız değişkenlerin anlamlılık düzeyleri hakkında bilgiler bulunmaktadır. Tabloya göre, 6 değişkenin modelin açıklamasında anlamlı bir katkısı olduğu gözlenmektedir. Modelde katkısı olmayan değişkenler ise modelden çıkarılmıştır. Tablodaki B değerleri, her bir bağımsız değişkenin etki katsayısını gösterir. Pozitif işaretli B değeri, ilgili değişkendeki artışın kişinin pazar kurdu olma olasılığını artırdığını (veya tavsiye alan olma olasılığını azalttığını), negatif işaretli B değeri ise kişinin tavsiye alan kişi olma olasılığını artırdığını (veya pazar kurdu olma olasılığını azalttığını) gösterir. SE değeri, ilgili değişkene ait standart hata terimini ifade eder. Wald istatistiği ise söz konusu değişkenin modelin açıklaması açısından sağladığı anlamlılığı test etmek için kullanılır. Wald istatistiği, (B/SEb)² formülüyle hesaplanır ve ilgili değişkenin istatistiksel olarak anlamlı bir katkı sağlayıp sağlamadığını belirler.
Wald katsayısına ilişkin tabloda, serbestlik derecesi (df) ve anlamlılık düzeyi (Sig.) değerleri verilmiştir. %5 anlamlılık düzeyinde, Medeni hal dışındaki tüm değişkenlerin modele anlamlı bir katkı sağladığı görülmektedir. En büyük etkiyi ise cinsiyet değişkeni sağlamaktadır, çünkü mutlak değeri en yüksek B değeri cinsiyet değişkenine aittir. Tablodaki son sütun olan Exp(B) değeri ise değişkenlerin etkisini ifade etmektedir. Pozitif işarete sahip B değerleri için Exp(B) değeri 1’den büyükken, negatif işarete sahip B değerleri için Exp(B) değeri 1’den küçüktür. Exp(B) değeri, ilgili değişkenin bir birimlik artışının öngörülen olayın olma olasılığındaki artışı ifade etmektedir. Örneğin, cinsiyet değişkeni 1’den 2’ye çıktığında, olasılık oranı 1.669 kat artacaktır.
Daha basit bir ifadeyle, cinsiyet değişkeninin iki değeri (1-Erkek ve 2-Kadın) vardır. Bir kişinin cinsiyeti erkek yerine kadın olduğunda, o kişinin pazar-kurdu olma olasılığı 1.669 kat artmaktadır. Bu da kadınların, erkeklere göre pazar-kurdu olma ihtimalinin daha yüksek olduğunu göstermektedir.
Öte yandan, “alışverişlerde başkalarına danışırım” ifadesine katılım derecesi açısından bir birimlik artış olduğunda, kişinin pazar-kurdu olma olasılık oranı %0.756 oranında azalacaktır. Bu da kişinin tavsiye alan biri olma olasılığının artacağını göstermektedir.
Verilerinizin analizi ve yorumlanması konusunda, akademik alanda her konuda yardıma ihtiyacınız varsa, uzman ekibimizle birlikte size yardımcı olmaktan mutluluk duyarız. Projelerinizin gereksinimlerini değerlendirebilir, size en uygun hizmetleri sunabiliriz. İletişime geçmek ve daha fazla bilgi almak için bize ulaşabilirsiniz.